WELCOME TO KOCERROXY
We are a one-stop solution for all your proxy needs.
Experience the best Residential and Datacenter proxies using our easy-to-use dashboard supported by our top-notch live support to help.
Get Trial BundleFEATURES
Making every step User-Centric
Say GoodBye to Connectivity Issues
Our residential and datacenter proxy services are designed to provide complete reliability with zero hassle. Our customers count on us for uninterrupted connections – every time!
Quality at Affordable Prices
Kocerroxy offers residential and datacenter proxies at prices that our customers love while still providing top-notch quality.

Possibly the Best Customer Support
Kocerroxy is renowned for our top-notch customer service. Our customers appreciate the prompt, efficient, and friendly support that we provide.
OUR SERVICES
What Type of Proxies are you looking for?
Residential Proxies
- A huge pool of 50 Million IPs from Worldwide Locations (User:Pass and IP auth)
- Country specific options to choose from only US, UK, DE, JP, ESP, DK, and more
- Expires in 60 Days from the time of redemption
- Supported Protocols: HTTP/SOCKS5
Datacenter Proxies
- Truly Unlimited bandwidth. Default Plans fixed at 500 threads
- Two Location Pools - USA and European Mixed
- Rotation on each request, with only IP Auth available
- Supported Protocols: HTTP/SOCKS5
PRICING
Simple, straight forward pricing
$
1.8
/GB
More and more etc.
INCLUDES
- A huge pool of 11M IPs from Worldwide Locations
- Option to choose from US, UK, DE, JP, IN, CA and many more
- User:Pass and IP authentication
- Supported Protocols: HTTP(S)SOCKS5
Starting From
$
2
INCLUDES
- Truly Unlimited bandwidth.
- Default Plans fixed at 500 threads.
- Custom plans are available.
- Two Location Pools - USA and European Mixed
- Only IP Auth available
- Supported Protocols: HTTP/SOCKS5
$
2
GET A BUNDLE OF
![]() Residential Proxies (400 MB)
Residential Proxies (400 MB)
![]() Datacenter Proxies (1 Day)
Datacenter Proxies (1 Day)
INCLUDES
- Residential Proxies (400 MB)
- Datacenter Proxies (1 Day)
- All the features from our Regular Plans for your full experience of our proxies
Get Full Access to Proxies for 24 Hours
We cater to all Residential Proxies Use Cases
HOME USE CASES

Automate Web Scraping
Social Media Management
E-Commerce & Automation
Anonymous Browsing
SEO
Online Gaming
Our Proxies are also best suited for
 view reviews on TRUSTPILOT
view reviews on TRUSTPILOT
What Our Customers Are Saying
“ Kocer is the most trustworthy and consistently high-quality provider out here. Never had one problem with them (authentication, CPM, support, quality). Need proxies to unlock blocked content? Residential proxies are just as fast. I averaged 6-7k CPM with them and never got locked/2fa accounts.
Lil Fork
2022-05-01

“ One of the best proxy provider. I really like the quality of DC & Residential ips. Price is very good not overpriced.
Omar El Moujahid
2022-12-18
“ I’ve been using this proxy service for a while. All I can say is that it’s worth every penny! Affordable and fast proxies! Highly recommended!
Sak Kalipz May 01, 2022
2022-05-01
“ Great proxies, excellent service. I recommend it to everyone! A must-try when you join is their live chat.
Gavin Steve
2022-07-06
BLOGS
Our Latest Blog Posts
View All ArticlesBECOME A PART OF THE BIGGEST REVOLUTION IN PROXY SERVICE
Introducing Our Redesigned User Experience
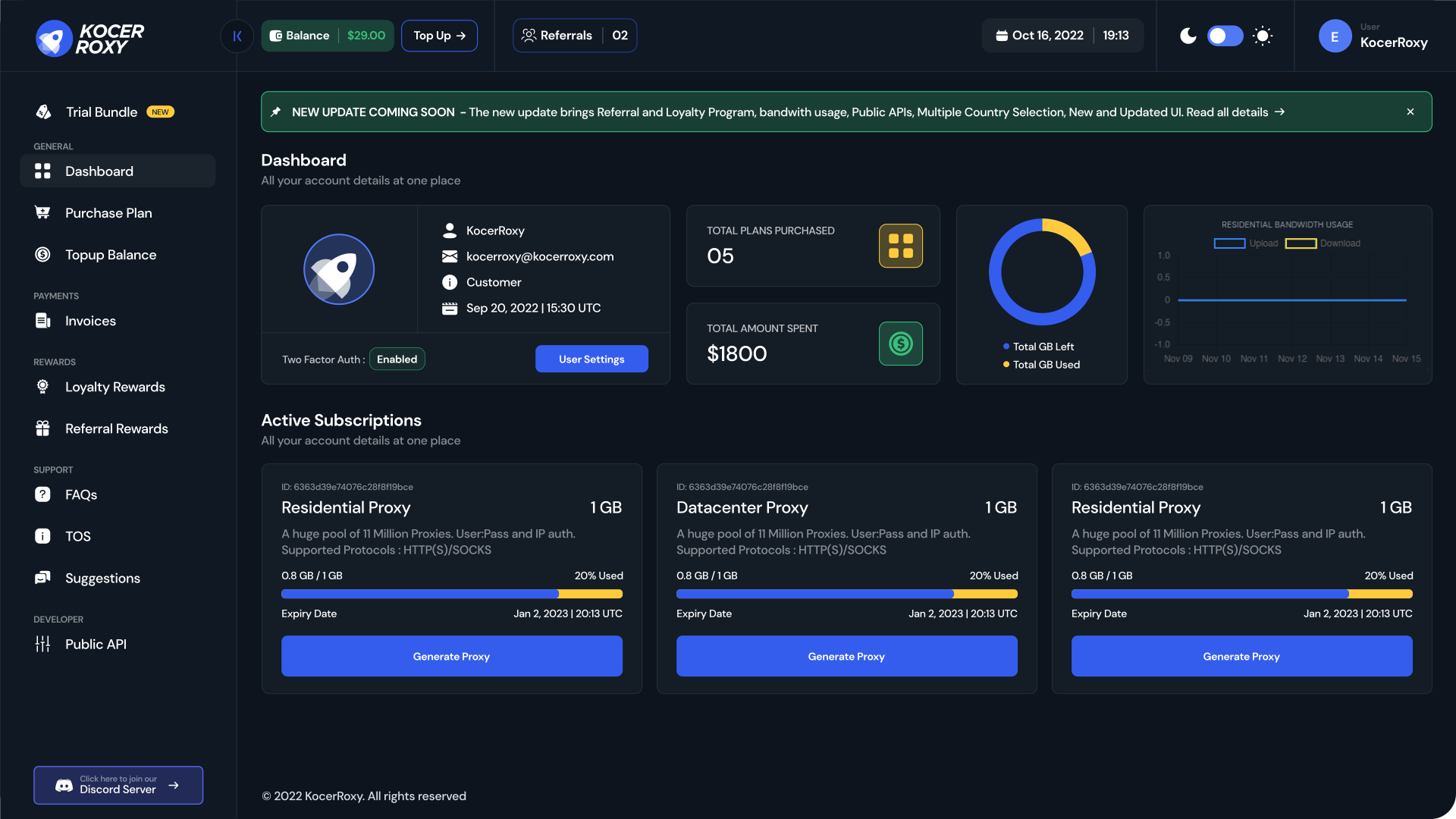
EXPERIENCE A NEW REVOLUTION IN PROXIES