
Imagine spending months building a machine learning model, fine-tuning every hyperparameter, and using the latest deep learning techniques only to realize your model performs terribly in the real world. It’s not because of the algorithm. Might not be because of your code—although you should always double-check your code. It’s because you didn’t follow the right approach when collecting data for machine learning.
This is why data collection is one of the most important steps in any machine learning project. It’s like cooking: no matter how skilled the chef is, a bad ingredient will ruin the dish. In ML, bad data leads to bad models—no exceptions.
Why High-Quality Data Matters in Machine Learning
The machine learning engineer and data scientist Mislav Jurić shared with me a great saying: “Garbage in, garbage out” (GIGO). This perfectly applies to machine learning. If you train your model on incomplete, biased, or low-quality data, your results will be unreliable, no matter how powerful your algorithm is.
Case Study: A Healthcare ML Model That Almost Failed Due to Poor Data
A team of researchers was building an ML model to classify patients based on medical symptoms. They had collected around 300 data samples, but they quickly noticed a major problem—the class distribution was highly uneven:
- Class 1: 20 samples
- Class 2: 130 samples
- Class 3: 130 samples
- Class 4: 20 samples
If they had split the dataset randomly, most of the Class 1 and Class 4 samples could have ended up entirely in the training or test set, making the real-world data and the test set have different class distributions. This would lead to non-representative test set results, as some classes could be underrepresented or left out completely.
Realizing the issue, they decided not to use random sampling and instead applied stratified sampling. This ensured that each class was proportionally represented in training, validation, and test sets, making sure the model learned from all classes.
Python code demonstrating how to apply stratified sampling to ensure proper class distribution
from itertools import chainimport numpy as npfrom sklearn.model_selection import train_test_split# Example dataset with class labelsX = []for i in range(0, 50): # creates 50 samples (just strings in this sample)sample_name = "sample_" + str(i)X.append(sample_name)y = list(chain(["0"] * 5, ["1"] * 20, ["2"] * 20, ["3"] * 5)) # creates 5 class 0 labels, 20 class 1 labels, 20 class 2 labels and 5 class 3 labelsX_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, stratify=y)print("Training labels distribution:", dict(zip(*np.unique(y_train, return_counts=True)))) # class 0: 4 data samples, class 1: 16 data samples, class 2: 16 data samples, class 3: 4 data samplesprint("Testing labels distribution:", dict(zip(*np.unique(y_test, return_counts=True)))) # class 0: 1 data sample, class 1: 4 data samples, class 2: 4 data samples, class 3: 1 data sampleAlso read: How to Prepare Effective LLM Training Data
Key Characteristics of High-Quality Datasets
When building a machine learning model, the quality of your dataset is everything. Even the most advanced model won’t perform well if it’s trained on biased, mislabeled, or unbalanced data. So, what makes a dataset high-quality? Let’s break it down.
1. Representativeness: Your Data Must Reflect the Real World
Imagine training a healthcare model to classify diseases, but most of your training data comes from patients in big-city hospitals. If you try using that model in rural areas where patient demographics, lifestyles, and common diseases are different, it might fail completely.
This happens when your dataset isn’t representative of the real-world population. If your model is supposed to mimic reality, your data should match that reality as closely as possible.
Always verify dataset representativeness by consulting domain experts before training a model. If you don’t have access to one, compare your dataset’s distribution with known real-world statistics.
2. Correct Labels: Human Validation Matters
Your model can only be as good as the labels it learns from. If the data is mislabeled, your model will learn the wrong patterns, making it unreliable in real-world scenarios.
A common mistake is trusting auto-labeled data or assuming that a non-expert can label data accurately. But bad labels = bad models.
Have humans in the loop for validation. Ideally, experts in the field should verify labels, especially in specialized areas like medicine, finance, and law. If manual labeling is too expensive, consider using active learning—where the model flags uncertain cases for human review.
3. Data Splitting Done Right: Avoiding Leaks and Ensuring Balance
A common approach when splitting data is randomly assigning samples to training, validation, and test sets. If your dataset is imbalanced—some categories have far fewer samples than others—this can cause serious issues.
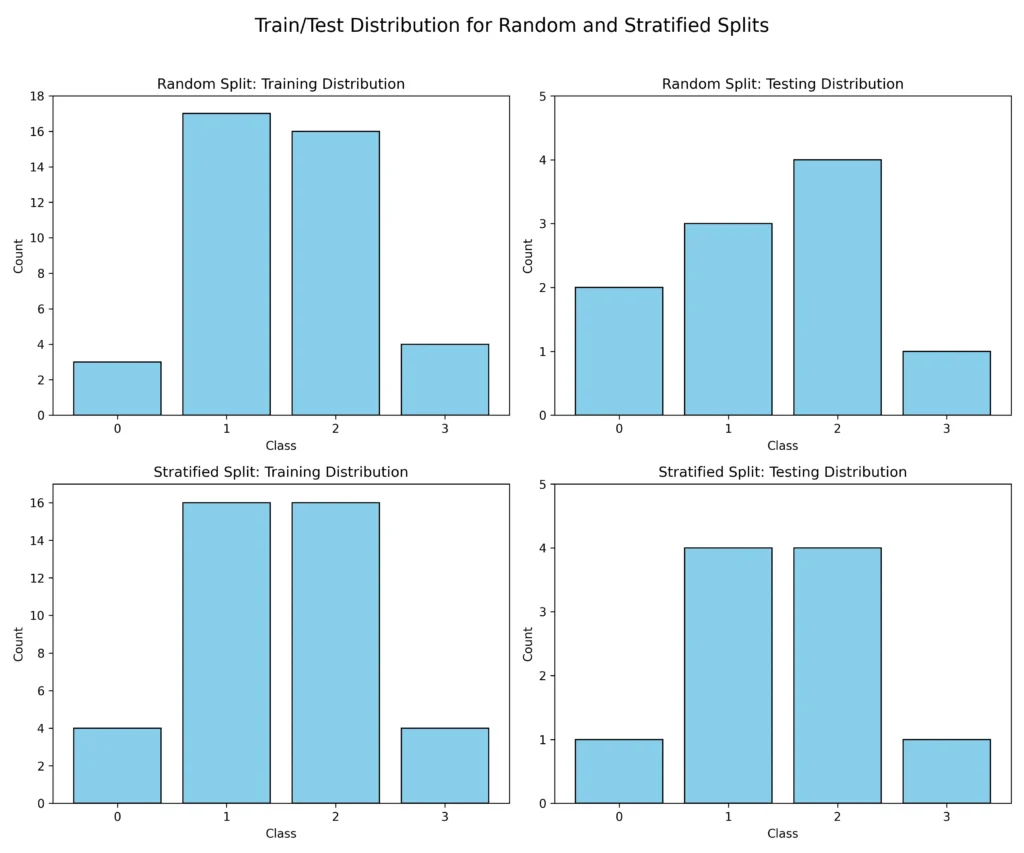
For example, if a rare class ends up mostly in the training set and barely in the test set, your test set results could be misleading.
Use stratified sampling to make sure each class is proportionally represented in the training, validation, and test sets. This prevents the model from ignoring rare classes and makes evaluation much more reliable.
Python code for checking class distribution before splitting:
import pandas as pdimport seaborn as snsimport matplotlib.pyplot as plt# Example datasetdf = pd.DataFrame({'Class': ['A', 'B', 'A', 'A', 'B', 'B', 'B', 'A', 'C', 'C']})# Count class distributionsns.countplot(x=df['Class'])plt.title('Class Distribution Before Balancing')plt.show()If you want to do hyperparameter tuning, you will also need to further split the training data into training and validation sets while keeping the class distribution in mind.
Also read: Data Parsing with Proxies
Common Data Sources for Machine Learning
Before you start training a machine learning model, you need data. But not all data sources are created equal. The source you choose depends on the problem you’re trying to solve and how structured or messy the data is. Let’s go through some of the most common data sources, along with their challenges and best practices.
Videos & Natural Language
Working with videos or text? You’ll need to preprocess it before you can feed it into an ML model. Depending on your use case, the extent of the preprocessing varies, but some preprocessing is almost always required.
In one project, a team collected videos of patients to train a healthcare ML model. But instead of feeding raw video files into the model, they extracted key data from the videos and converted it into structured JSON files. This made it easier to analyze and train on.
If you’re dealing with videos, consider extracting metadata (timestamps, object tracking, facial landmarks, etc.) into structured formats like JSON before moving forward.
If working with natural language, tokenizing the text—and depending on the machine learning model used, cleaning the text—would be required before training the model.
APIs vs. Web Scraping
If you need large amounts of data from the web, you have two main options:
- APIs (Application Programming Interfaces)
- Web Scraping
APIs are usually the better choice because they provide structured, reliable data without violating terms of service. Many platforms (Twitter, Google, OpenWeather, etc.) offer APIs for developers to access clean, formatted data.
Example of a simple API call using Python:
import requestsresponse = requests.get("https://api.openweathermap.org/data/3.0/onecall?lat=LATITUDE&lon=LONGITUDE&appid=YOUR_API_KEY")data = response.json()print(data)On the other hand, web scraping is often a last resort when APIs aren’t available or are too restrictive. However, it comes with challenges like:
- Websites changing layouts, which can break your scrapers.
- Legal issues—many sites prohibit scraping in their terms of service.
- Data inconsistency—unstructured HTML can be messy to parse.
Manually Collected Data
Sometimes, the best way to get high-quality data is to collect it manually. This might seem tedious, but in many cases, manually labeled or curated datasets perform better than automatically gathered ones.
If your use case requires domain-specific knowledge, manual data collection and curation can be worth the effort. Consider a hybrid approach—automated data collection, followed by human validation of key samples.
Also read: The Importance of Web Scraping
Handling Real-Time Data Collection
When collecting data for machine learning, things get even more complicated when dealing with real-time data. Unlike static datasets that you collect once and clean up later, real-time data is constantly changing—which means you need a system that can adapt on the fly.
So how do you handle it properly? Let’s go over the key strategies.
JSON for Dynamic Data
When dealing with real-time user-generated data, one of the best formats for storing it is JSON. Why? Because JSON is flexible—it can handle new data fields without breaking everything.
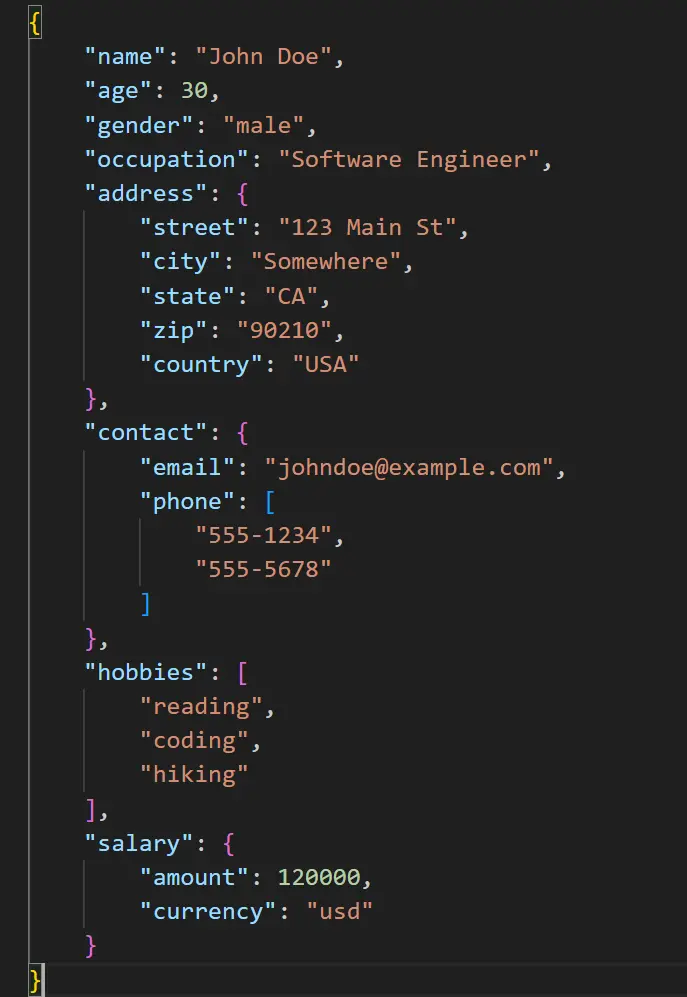
But even JSON-based data can evolve over time. For example, new data points might be added, or the structure might change slightly. When that happens, your data processing scripts need to be updated to handle the changes smoothly.
Here’s a sample Python code for handling missing fields within a JSON by replacing them with a provided default value:
import json# Example JSON with missing/extra fieldsjson_data = '{"name": "John", "age": 30}'parsed_data = json.loads(json_data)# Handling missing keys with default valuesname = parsed_data.get("name", "Unknown")city = parsed_data.get("city", "No City Provided")print(f"Name: {name}, City: {city}")Use JSON for flexibility, but plan for changes. If the JSON structure evolves, make sure older scripts don’t break by handling missing or new fields properly.
Storage Choices
When collecting real-time data, you need to store it somewhere. The two most common options are:
- Databases. Ideal for structured data that needs frequent querying.
- Cloud Storage (e.g., AWS S3, Google Cloud Storage). Better for large-scale, less frequently accessed raw data.
Also read: JSON vs. CSV: Which Is Better?
Cleaning and Preparing Data for ML
Once you’ve collected your data, the next step is cleaning and preparing it before training your model. This is where a lot of people cut corners—but skipping this step leads to garbage results no matter how good your algorithm is.
Here’s how to do it the right way to ensure your model learns from clean, structured, and unbiased data.
Ensuring Data is Ready for Use
The first thing you need to ask yourself is: “Can my data be trusted?”
Raw data is never perfect—it often contains errors, inconsistencies, and missing values. If you don’t catch these issues early, your model will learn from bad data, leading to poor performance in real-world scenarios.
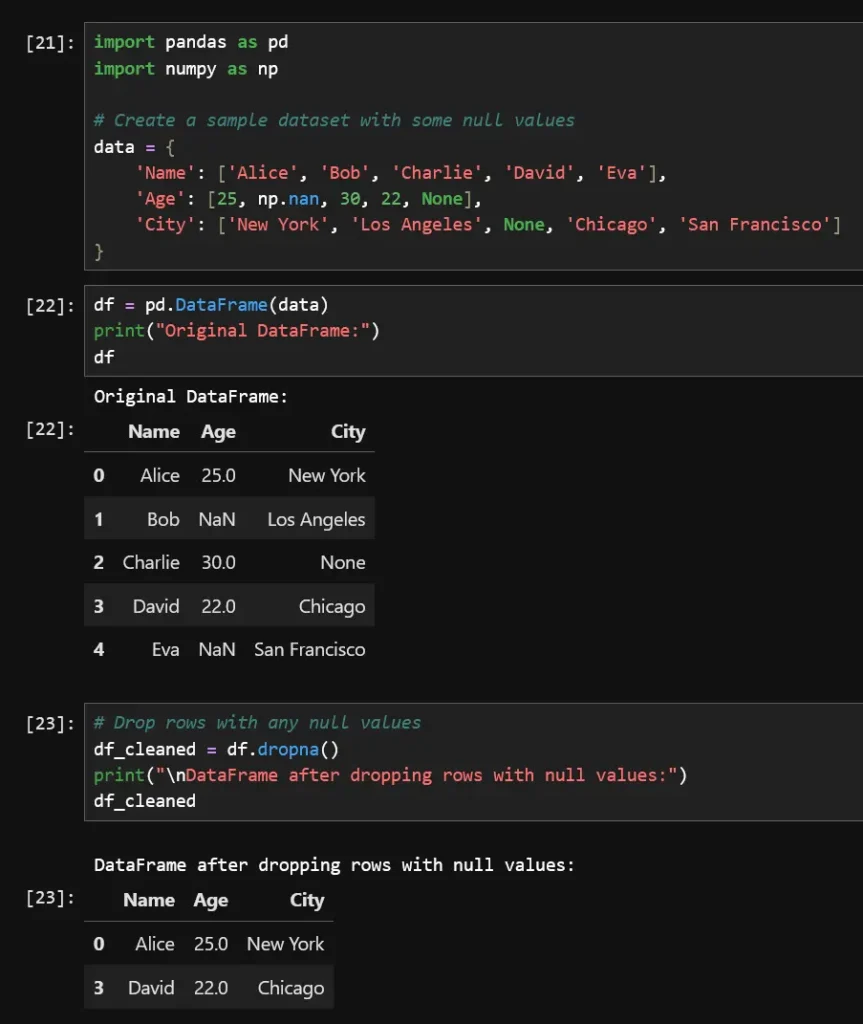
Python script for removing duplicate rows and imputing missing values using pandas:
import pandas as pd# Sample dataset with missing valuesdf = pd.DataFrame({'Name': ['Alice', 'Bob', None, 'Charlie', 'Bob'], 'Age': [25, 30, 35, None, 30]})# Drop duplicates and fill missing valuesdf = df.drop_duplicates().fillna({'Age': df['Age'].median()})print(df)Always have humans review the data, especially if labeling errors could significantly impact your results. Use double-checking methods—such as multiple reviewers for critical datasets.
Handling Unstructured Data
Not all data comes neatly packaged in tables. If you’re dealing with unstructured data like text, images, or videos, there’s no one-size-fits-all approach—you need a plan based on your specific use case.
Understand your data before deciding on the best way to structure it. Use Python scripts (pandas, OpenCV, or NLP libraries) to convert, clean, and format unstructured data.
Mitigating Bias
One of the biggest mistakes in machine learning is assuming your dataset is neutral and unbiased. It almost never is.
Bias sneaks into datasets in different ways—imbalanced class distributions, unverified data sources, or human labeling errors. If you don’t test for bias, you might end up with a model that reinforces unfair patterns rather than making fair and accurate predictions.
Instead of assuming your dataset is unbiased, train your model and analyze its behavior. Check for disproportionate error rates across different classes—this often indicates bias. If you find bias, adjust the dataset (e.g., by adding more samples from underrepresented classes) rather than just tweaking the model.
Also read: Alternative Data for Startups
Tools & Technologies for Data Collection
Having the right tools can make collecting data for machine learning much easier and more efficient. Whether you’re scraping data from the web or cleaning raw datasets, the right technology can save you time and prevent errors.
Here are some essential tools that can help you streamline your data collection process.
1. Web Scraping: Scrapy
If you need data from the web and an API isn’t available, web scraping can be a useful approach. One of the best tools for this is Scrapy—a powerful Python framework that makes web scraping easier and more efficient.
A simple Scrapy script to extract website data:
import scrapyfrom scrapy.crawler import CrawlerProcessclass QuotesSpider(scrapy.Spider):name = "quotes"start_urls = ['http://quotes.toscrape.com/']def parse(self, response):for quote in response.css('div.quote'):yield {'text': quote.css('span.text::text').get(),'author': quote.css('small.author::text').get()}process = CrawlerProcess(settings={"FEEDS": {"items.json": {"format": "json"},},})process.crawl(QuotesSpider)process.start() # the script will block here until the crawling is finishedUse Scrapy when you need structured data from websites but no API exists. Be aware of legal and ethical concerns—always check a website’s terms of service before scraping.
2. Data Processing: Pandas
Once you’ve collected data, the next step is cleaning and transforming it. That’s where pandas comes in. Pandas is a Python library designed for data manipulation, cleaning, and preprocessing. It’s one of the most commonly used tools in machine learning workflows.
Use pandas for data cleaning, transformation, and analysis before feeding data into your model. When working with JSON, CSV, or databases, pandas helps structure the data properly.
3. Checking Data Integrity: Custom Python Scripts
Even if your data looks clean, small mistakes can lead to huge problems when training your model. Sometimes, you need custom scripts to verify that your data follows the correct structure.
A team was using a large language model (LLM) like ChatGPT to generate structured responses for a dataset. However, over time, they noticed that some responses contained gibberish or incorrect formatting.
To solve this, they wrote a Python script that checked if the generated responses matched the expected structure. While it couldn’t verify content accuracy, it helped them filter out bad responses automatically, saving hours of manual work.
Also read: The Future of Ad Verification: AI’s Impact on Brand Safety
A Real-Life Case Study: Collecting Medical Data
Collecting data for machine learning is already tricky—but it becomes even more challenging when privacy and legal compliance are involved. In fields like healthcare, where sensitive patient data is collected, mistakes can lead to serious ethical and legal issues.
Here’s a real-world case where a team had to collect and process medical video data while ensuring patient privacy—and the smart solutions they used to solve this challenge.
The Challenge: Collecting Medical Video Data While Protecting Privacy
A healthcare research team was working on a machine learning model that analyzed medical videos to help with diagnostics. However, there was a major issue: the videos contained identifiable patient information.
They couldn’t just store and process the videos as they were because:
- Patient names were visible in medical records attached to the video files.
- The patients’ faces and body features were clearly visible in the footage.
- They had to comply with strict privacy laws like GDPR.
If they didn’t handle this correctly, the entire project couldn’t move forward due to ethical and legal risks.
How They Solved It
The team found two effective solutions:
1. Data Anonymization: Replacing Patient Names with Auto-Generated Strings
To protect patient identities, they automated the anonymization process:
- Instead of storing real patient names, they generated random strings (e.g., Patient_001, Patient_002) and assigned them to each individual.
- The mapping between real names and assigned strings was stored in a separate, highly restricted database, accessible only to authorized personnel.
- This ensured that even if the dataset was leaked, it wouldn’t expose patient identities.
2. Video Blurring: Hiding Identifiable Features
To prevent visual identification, they used computer vision techniques to blur patient faces:
- They applied key point detection to identify facial landmarks like the eyes, nose, and mouth.
- Once key points were detected, they automatically blurred the surrounding region.
- The same approach was used to blur any tattoos, scars, or other identifiable body parts.
They used a machine learning model for detecting key points on the body and OpenCV for blurring the areas around the detected key points.
Did it work? Yes! Even when a patient turned their head to the side or wore hats, the key point detection still functioned well, ensuring their identity remained protected.
Lesson Learned: Privacy Should Be Handled from the Start
One of the biggest takeaways from this project? Never treat privacy as an afterthought.
If they had waited until the later stages of development to address privacy concerns, they would potentially have had to redo large portions of their work—wasting time and resources.
Think about privacy from the very beginning—especially when working with sensitive data. Automate anonymization and security measures so privacy protection is built into the data collection process. Consult legal experts early to avoid compliance headaches later. Regularly assess and update your privacy protocols to adapt to evolving regulations and technological advancements. By prioritizing transparency with users about how their data will be used, you can build trust and mitigate potential privacy issues in AI technologies. Ethical data practices safeguard individuals and enhance the credibility of your organization.
Also read: Well Paid Web Scraping Projects
Getting Started with Machine Learning
If you’re new to machine learning, it can feel overwhelming at first. Where do you start? What tools should you use? How do you go from raw data to training a real model?
Don’t worry—I’ve got you covered. Here’s a beginner-friendly roadmap to help you learn, practice, and build your first machine learning project.
Read a Great Beginner-Friendly ML Book
Before diving deep into machine learning, it helps to understand the basics of machine learning. A great book to start with is Hands-On Machine Learning by Aurélien Géron.
- It covers real-world machine learning workflows, including data preprocessing.
- The explanations are clear and beginner-friendly.
- It includes Python code examples so you can follow along and practice.
Read the book before jumping into complex projects—it will help you understand many of the machine learning models used today.
Start with Kaggle
One of the best places to learn and practice machine learning is Kaggle. Kaggle is a website where you can:
- Find real-world datasets for free.
- Solve machine learning challenges (some with prize money!).
- See how experienced data scientists approach problems—you can study their solutions and improve your skills.
Instead of struggling to find data, Kaggle provides ready-to-use datasets in various domains—healthcare, finance, sports, and even fun topics like movie ratings and music preferences. It’s a hands-on way to learn without getting stuck in the data collection phase.

Pick a simple dataset on Kaggle and try to clean, analyze, and visualize it using Python. Pandas is a great tool for this!
Build Your First Data Collection Project
Once you’ve read a bit about ML and practiced on Kaggle, the next step is to collect your own dataset and train a machine learning model on that dataset.
Example Project: Collect movie scripts and train a text-generation model!
Here’s how Mislav Jurić did in his project: Movie Script Generator Using GPT-2.
- Found a movie scripts database online.
- Used web scraping (Scrapy) to collect the movie scripts.
- Trained a GPT-2 model on the data to generate new movie scripts.
Start small—don’t try to collect massive datasets right away. Choose a fun dataset so you stay motivated while learning.
Also read: Web Scraping With Proxies
Conclusions on Collecting Data for Machine Learning
If there’s one thing you should take away from this guide, it’s this: data quality is king.
You can have the most advanced machine learning model, fine-tuned with the latest techniques, but if it’s trained on bad data, it’s going to fail. No exceptions.
What’s the fix? Collecting data the right way from the start. Don’t just grab whatever data is available. Think about what’s truly representative of your problem. Involve domain experts who can spot issues in your dataset that an algorithm never will.
A mediocre model trained on a high-quality, well-balanced dataset will always outperform a powerful model trained on garbage data.
So, take the time to collect, clean, and validate your data properly. Your future ML model and your sanity will thank you.


