
JSON and CSV are two commonly encountered formats for efficient data handling. Whether you’re scraping websites, managing APIs, or analyzing datasets, understanding the nuances of the JSON vs. CSV comparison can make or break your project.
JSON, short for JavaScript Object Notation, is a format designed to represent complex, hierarchical data in a way that’s both human-readable and machine-friendly. On the other hand, CSV, or Comma-Separated Values, organizes data into simple rows and columns, making it perfect for flat, tabular datasets.
Choosing between JSON and CSV means understanding how these formats perform in specific scenarios. For instance, CSV shines when you’re building a list of contacts or tracking city temperatures over time. JSON, however, becomes indispensable when you’re saving web pages with multiple attributes, such as a product’s name, price, and description.
This article dives deep into the differences between JSON and CSV, breaking down their structures, strengths, and weaknesses. By the end, you’ll know exactly which format to use for your next project—whether you’re a developer working with APIs or a data enthusiast organizing your latest scraping adventure.
Key Structural Differences
The main difference between JSON and CSV lies in how they organize and represent data. While CSV relies on a simple row-and-column structure, JSON offers a more flexible, hierarchical format that can handle complex relationships. Let’s break it down.
CSV: Rows, Columns, and Simple Delimiters
CSV organizes data into rows and columns, separated by delimiters like commas or tabs. Each line in a CSV file represents a single record, and each column holds a specific attribute of that record. This simplicity makes CSV easy to read and process, especially when working with flat, tabular datasets.
For example, if you’re scraping a list of city temperatures, a CSV file might look like this:
City,Date,Temperature New York,2025-01-01,3 London,2025-01-01,7 Seoul,2025-01-01,-2 But things get tricky when your data has complex relationships, like a product catalog with multiple attributes. To represent this in CSV, you might need extra columns or rows, leading to redundancy and making the structure harder to manage.
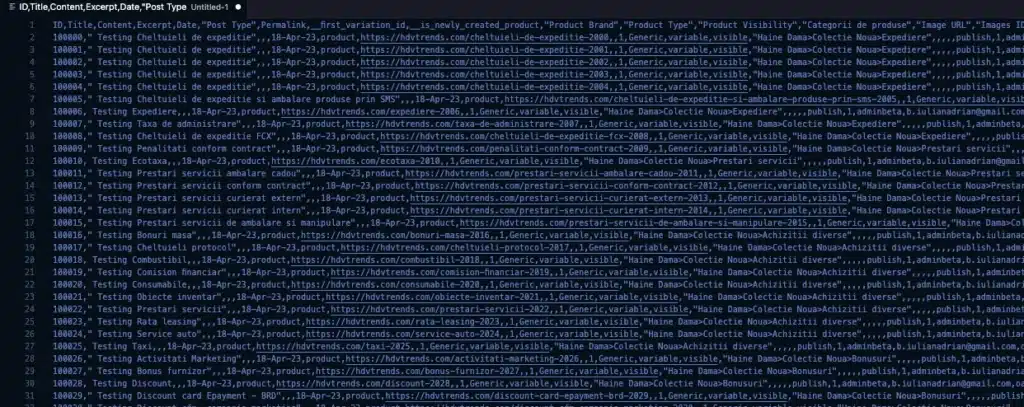
For instance, storing multiple attributes for each product:
ProductID,Name,Category,AttributeName,AttributeValue 1,Smartphone,Electronics,Color,Black 1,Smartphone,Electronics,Storage,128GB 2,Laptop,Computers,Color,Silver 2,Laptop,Computers,Storage,512GB Notice how ProductID and other details repeat across rows to accommodate each attribute. This works but can quickly become unwieldy with larger datasets.
JSON: Flexible and Hierarchical
JSON, on the other hand, organizes data into a hierarchy of nested objects and arrays. It’s more like a tree, where each object can contain other objects or lists. This makes it perfect for storing structured data with parent-child relationships.
Here’s how the same product catalog would look in JSON:
[ { "ProductID": 1, "Name": "Smartphone", "Category": "Electronics", "Attributes": { "Color": "Black", "Storage": "128GB" } }, { "ProductID": 2, "Name": "Laptop", "Category": "Computers", "Attributes": { "Color": "Silver", "Storage": "512GB" } } ] Here, all attributes are neatly nested within each product object, avoiding redundancy and keeping related data grouped together.
JSON’s hierarchical structure is powerful, but it can quickly become difficult to read, especially when working with deeply nested data. This is where JSON beautifiers come in handy. Tools like JSON Formatter automatically format and indent JSON, making it much easier to scan and debug.
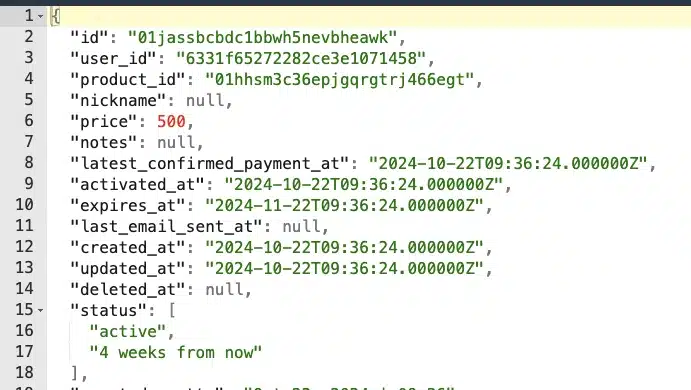
Instead of sifting through a long, unformatted string, a beautifier presents the data in a structured and readable way. Whether you’re manually reviewing API responses, debugging a web scraping output, or simply organizing complex data, using a JSON beautifier can save time and reduce errors by clearly displaying relationships between objects and values.
Also read: Data Parsing with Proxies
Use Cases: When to Choose JSON vs. CSV
The type of data you’re working with and your intended use will determine which format is best for you. Both formats have their strengths, and understanding when each one excels can save you time and effort in managing your data.
When to Choose CSV
CSV is perfect for simple, flat datasets where data can be easily organized into rows and columns. This makes it the ideal choice for tasks like contact lists, temperature logs, sales reports, or inventory lists where each row represents one data point or item.
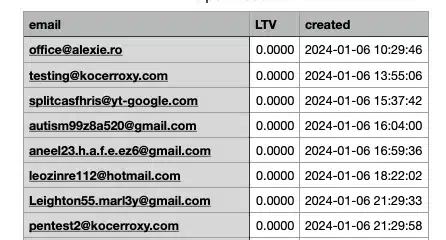
For example, if you’re scraping email addresses and phone numbers, a CSV file might look like this:
Each record fits neatly into a row, with no need for extra structure.
CSV’s simplicity also makes it a go-to format for working with spreadsheets or importing/exporting data between systems, as most databases and tools natively support it.
When to Choose JSON
JSON shines when your data is complex or hierarchical. It’s ideal for scenarios where you need to represent relationships or store nested attributes like website attributes or application data.
Imagine you’re scraping a site with multiple pages, each containing attributes like title, price, and description. JSON handles this effortlessly:
{ "Page": 1, "Title": "Best Smartphones", "Products": [ { "Name": "Smartphone A", "Price": "$699", "Features": ["5G", "128GB Storage", "Black"] }, { "Name": "Smartphone B", "Price": "$899", "Features": ["5G", "256GB Storage", "Silver"] } ] } This structure keeps related data grouped together and avoids the repetition you’d encounter in CSV.
Also read: How to Gather Emails from LinkedIn?
Handling Large Datasets
When working with large datasets, both JSON and CSV present unique challenges and opportunities. The right choice depends on your workflow and how you plan to process the data. Let’s explore how each format handles large-scale data and the trade-offs involved.
CSV: Line-by-Line Processing
CSV’s simplicity makes it well-suited for handling large datasets, particularly when you only need to process data sequentially.
Imagine you’re analyzing millions of temperature readings for cities over a year. Each entry can be processed line by line. Since CSV files are just plain text with delimiters, you can easily load and process one line at a time without loading the entire file into memory.
When relationships between rows are needed (e.g., parent-child data), CSV often requires duplicating information. This increases file size and can complicate processing.
JSON: Streaming Parsers and Hierarchical Data
JSON’s hierarchical structure is both a strength and a weakness for large datasets. It allows for rich data representation but often requires reading the entire file to parse the relationships. Solutions like streaming parsers help alleviate this issue.
If you’re scraping data from a multi-page e-commerce site, JSON can represent attributes for products, pages, and categories in a nested structure:
{ "Page": 1, "Products": [ { "Name": "Product A", "Price": "$100" }, { "Name": "Product B", "Price": "$200" } ] } Streaming parsers can process JSON incrementally, allowing you to handle large files without loading them fully into memory. This is particularly useful for log files where each line contains a JSON object.
JSON’s nested nature means you often need the full structure to make sense of the data. Parsing can be slower if you’re working with deeply nested or highly complex files.
Also read: How to Prepare Effective LLM Training Data
Performance and Efficiency
When it comes to performance and efficiency in web scraping, JSON and CSV handle data differently. However, the format you choose often has less impact on overall performance than you might think.
JSON and CSV each have strengths depending on the use case, but in practice, the differences in processing speeds are usually negligible compared to other bottlenecks.
In web scraping, network latency often overshadows any differences in file processing speeds.
Downloading a webpage or API response might take several seconds due to network delays, while saving or parsing the data (whether JSON or CSV) happens in milliseconds. For instance, scraping an e-commerce site might involve waiting 10 seconds for a page to load while storing the data takes less than 1 second, regardless of the format.
Also read: The Hidden Honeypot Trap: How to Spot and Avoid It While Scraping
Data Integrity and Error Handling
When working with JSON and CSV, data integrity and error handling can vary significantly. Choosing the right format often depends on how you handle potential issues like parsing errors or misaligned data.
JSON: Strict Parsing Rules and Clear Error Reporting
JSON is designed to be strict about its structure, which is both a strength and a potential inconvenience.
JSON parsers enforce specific rules, like properly closed braces and correctly formatted key-value pairs. If there’s an error, such as a missing comma or an unmatched bracket, the parser will fail immediately and provide clear error messages.
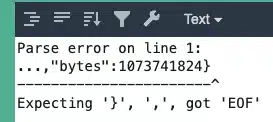
Suppose you’re scraping product data from an API, and the JSON response is incomplete or malformed. Your JSON parser will likely throw an error pinpointing the exact issue, helping you quickly identify and fix it.
This strictness reduces the chances of accidentally working with corrupted or incomplete data. For instance, if you’re processing a nested JSON file with customer orders, you can be confident that all elements adhere to the expected structure unless an error is explicitly thrown.
CSV: Forgiving but Prone to Misalignment
CSV is less strict, which can be both an advantage and a challenge, especially when data integrity is crucial.
CSV parsers tend to overlook minor formatting issues. For example, if one row is missing a value, the parser might fill in a blank automatically, allowing processing to continue without interruption.
If you’re scraping a table of user data and one row has fewer columns than expected, the parser might still process the file but could misalign rows and columns, leading to hard-to-detect data corruption.
Misaligned rows or incorrectly escaped delimiters (like commas within quoted fields) are frequent issues. For instance, if a product description contains a comma but isn’t properly enclosed in quotes, it could cause the parser to misinterpret the data structure.
Also read: Alternative Data for Startups
Compatibility and Integration
When deciding between JSON and CSV, consider how these formats work with programming languages, databases, and APIs. Both are widely supported, but they have unique strengths that affect how easily you can move and process data.
JSON and CSV interact differently with databases and APIs, with CSV leaning towards ease of use and JSON offering more flexibility for complex data structures.
CSV: Easy Import/Export Across Platforms
CSV’s tabular format aligns naturally with databases, which are often structured around rows and columns. This makes CSV a go-to for importing and exporting data.
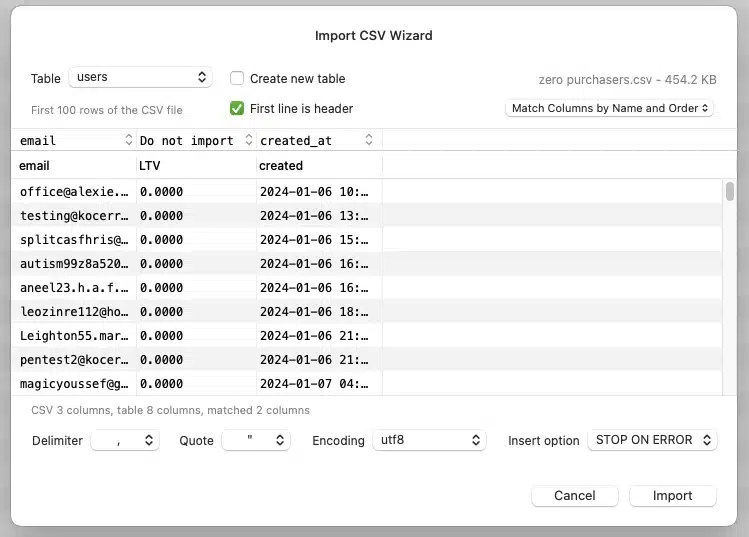
Tools like MySQL and PostgreSQL include straightforward CSV import/export options, allowing you to move data between platforms with minimal adjustments. This makes CSV a favorite for tasks like bulk loading user data or migrating datasets between tools.
JSON: Cross-Tool Compatibility Challenges
JSON’s flexibility allows it to represent complex relationships, but this can create inconsistencies when moving data between tools. While many databases, like MongoDB or PostgreSQL, support JSON natively, they may require adjustments to the file’s structure before importing.
Imagine scraping e-commerce site data where product details include nested attributes like sizes and colors. While JSON can capture this hierarchy elegantly, exporting this data into a relational database often requires flattening the structure into tables—a process that demands extra processing steps.
Also read: Inspect Element Hacks: Techniques for Analyzing Websites
Security Considerations: JSON vs. CSV
When working with data in JSON or CSV formats, security might not be the first thing that comes to mind. However, overlooking security considerations can expose your systems to exploits or vulnerabilities. Here’s what you need to know to keep your data handling secure and reliable.
Keep Parsing Libraries Updated
No matter which format you’re using, outdated parsing libraries can leave you vulnerable to known exploits. Attackers can leverage these vulnerabilities to execute malicious code or inject harmful data into your system.
If you’re working with a JSON parsing library in Python or Node.js, an unpatched version might mishandle unexpected or malformed data, causing your application to crash or behave unpredictably.
Regularly check for updates to the libraries you’re using. Tools like npm, pip, or package managers in other languages often alert you to new versions. Apply updates promptly to protect against newly discovered vulnerabilities.
Also read: Free Libraries to Build Your Own Web Scraper
Emerging Trends and Future Directions
As data formats evolve alongside technology, JSON and CSV remain staples in the data world. However, emerging trends hint at shifts in how these formats are used, particularly in configuration management and workflows like web scraping. Here’s a look at what’s changing and what it means for developers.
The Rise of YAML for Configuration
In recent years, YAML (Yet Another Markup Language) has gained traction as a preferred format for configuration files. Unlike JSON and CSV, YAML emphasizes readability and supports advanced features like comments and multi-line strings.
JSON’s strict syntax, including the need for quotes and commas, makes it less human-friendly for complex configurations. YAML simplifies this by eliminating extra characters and allowing more intuitive formatting.
A Docker docker-compose.yml file is far easier to manage and understand compared to its JSON equivalent.
services: app: image: my-app:latest ports: - "8080:8080"In JSON, this would be much harder to read and modify due to its verbose structure.

Tools like Kubernetes and Ansible are driving the YAML adoption wave. If you’re setting up workflows in these environments, understanding YAML is becoming a must. JSON and CSV still have their place but are less common for these specific use cases.
Web Scraping Workflows and YAML
While YAML excels in configuration, JSON and CSV continue to dominate for web scraping. However, YAML’s growing popularity indirectly influences scraping workflows:
YAML is increasingly used for defining scraper settings, such as target URLs, headers, or parsing rules. This allows for more maintainable and reusable scraper configurations.
A YAML file can store your scraper rules:
scraper: target_url: "https://example.com" headers: User-Agent: "Mozilla/5.0" fields_to_extract: - title - date - priceSome scraping frameworks now come with built-in support for YAML configuration, simplifying the process of adjusting settings without the need to modify code.
Despite YAML’s rise, JSON and CSV remain critical:
- JSON for Data Exchange: APIs and web services still overwhelmingly rely on JSON for data exchange due to its lightweight and widely supported structure.
- CSV for Simple Exports: CSV continues to be the go-to format for exporting scraped data into spreadsheets or integrating with analytics tools.
Also read: Well Paid Web Scraping Projects
Conclusion
There’s no universal answer to whether JSON or CSV is better—it depends on the context. CSV works best when your data is simple, and you need quick compatibility with databases or tools like Excel. JSON is your go-to for complex structures or when working with APIs.
Understand your dataset’s needs. If you’re logging basic metrics, CSV will likely do the job. But if you’re scraping a multi-layered website or need to represent detailed relationships, JSON is the clear winner. By aligning the format with the data, you’ll streamline your workflow and avoid unnecessary headaches.


